基本概念
并行计算
并行计算是指,在并行机上,将一个应用分解成多个子任务,分配给不同的处理器,各个处理器之间相互协同,并行地执行子任务,从而达到加速求解速度,或者求解大规模应用问题的目的。
并行计算的目的
快速解决大型且复杂的计算问题:很多问题是相当庞大而复杂的,尤其是当计算机的内存受到限制的时候,用单个计算机来解决是不切实际或者根本不可能的。
节省时间和成本:理论上,使用更多的资源会使一个任务提前完成,而且会节约潜在的成本。况且可以使用便宜的、甚至市面将要淘汰的cpu来构建并行集群。
使用非本地资源:当缺少本地计算资源的时候可以使用广泛的网络或因特网计算资源。
强扩展与弱扩展
强扩展性(Strong Scalability)表示问题规模不变,变化处理器的数量,看性能的提升,用加速比来衡量。加速比(强可扩展性),P个处理器的加速比=单个处理器时间/P个处理器时间。
例如,一个算法原来使用单个处理器需要的时间是2000s,而后面用了P个处理器后只需要1000s,那么加速比便为2倍,即speedup=2000/1000=2 ,同理如果变成了20s的话,那么加速比便是100倍。
在强扩展性中,还会收到Amdahl法则的影响。指的是在一个算法中,有一部分可以平行计算,其余部分必须串行计算,因此加速比的计算公式为
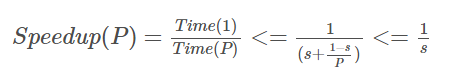
对于可扩展性的描述,某些情况下会有一些特别的称谓.如果在增加进程/线程的个数时,可以维持固定的效率,却不增加问题的规模,那么程序称为强可扩展的(强可伸缩性)。如果在增加进程/线程个数的同时,只有以相同倍率增加问题的规模才能使效率值保持不变,那么程序就称为弱可扩展的(弱可伸缩性)。
如何判别kernel是计算密集还是访存密集
分析程序是计算密集(compute intensive)还是访存密集(Memory intensive)
1)算出机器的单核峰值性能
主频*SIMD宽度*2(如果存在乘加指令)--> CpuPeak
2)测出机器峰值带宽
用streaming测出实际带宽峰值,但是该峰值是所有处理器核的总和,需要除以实际物理核数(超线程不算),算出峰值带宽-->MemPeak
3)分析算法的计算访存比
加减乘除都算一次操作(连续的乘加操作算一次);单次访存算一次操作(如果会用到非连续数据,那么要按cacheline长度算,因为机器实际会按照cache line读取数据);
计算强度-->flop/Bytes
4)结论:
if CpuPeak/MemPeak > Flop/Byptes, then 访存密集 else 计算密集
什么样的程序是memory-bound?
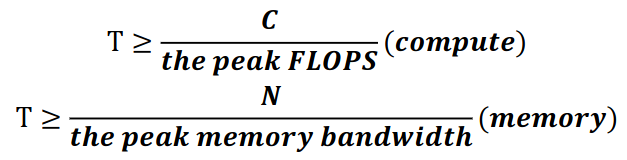
后者远大于前者时是memory bound。
MPI与OpenMP
MPl(Message Passing Interface)是函数库规范,而不是并行语言,操作如同库函数调用,是一种标准和规范,而非某个对它的具体实现(MPICH等),与编程语言无关,是一种消息传递编程模型,并成为这类编程模型的代表。
OpenMP是共享存储体系结构上的一个并行编程模型或基于线程的并行编程模型。
SIMD与SIMT
SIMD(Single Instruction, Multiple Data)和 SIMT(Single Instruction, Multiple Threads)都是并行计算中常见的概念,用于提高处理器对数据并行操作的支持能力,但它们应用于不同的计算架构和环境中。
SIMD: 一条指令流(一串顺序的SIMD指令),每条指令对应多个数据输入(向量指令),SIMT: 多个指令流(标量指令)构成线程, 这些线程动态构成warp。一个Warp处理多个数据元素
带宽与延迟
在计算机系统和网络中,性能指标通常涉及到延迟(Latency)和带宽(Bandwidth)。这两个指标都是衡量系统或网络效率和性能的重要标准,但它们所表示的内容和应用场景有所不同。
延迟(Ltency)是指从发送数据请求到接收到第一个响应之间的时间间隔。具体来说,延迟衡量了数据或指令在系统中传输和处理所需的时间。一般来说,延迟可以分为以下几类:
- 传输延迟(Transmission Latency): 发送数据从一个地点到另一个地点所需的时间,主要受到信号传播速度、传输介质和距离的影响。
- 处理延迟(Processing Latency): 数据或指令在接收端或处理器上处理所需的时间,取决于处理器的速度和负载情况。
- 队列延迟(Queueing Latency): 数据或指令在传输过程中等待处理的时间,特别是在高负载情况下,队列可能会导致延迟增加。
延迟对实时性要求高的应用非常重要,如视频会议、交易系统等。较低的延迟意味着系统响应更加迅速和及时。
带宽(Bandwidth)是指在单位时间内从一个点到另一个点传输的数据量。它通常用来描述网络连接或系统总线的数据传输能力。带宽可以表示为数据传输速率,例如每秒传输的位数或字节数。
- 网络带宽(Network Bandwidth): 指在网络连接中每秒传输的数据量,通常以 Mbps(兆位每秒)或 Gbps(千兆位每秒)为单位。
- 系统总线带宽(Bus Bandwidth): 指系统内部数据传输的速率,如内存总线的传输速度。
带宽决定了系统或网络能够同时处理的数据量大小。高带宽通常表示系统可以支持更多的并发操作和大量数据传输,从而提高整体的吞吐量。
有效带宽:

互连网络(Interconnection Network)的特征
- Topology(拓扑结构)拓扑结构指定了互连网络中节点和链接的布局方式。不同的拓扑结构影响了网络的性能、可靠性和成本效益。
- Routing Algorithm(路由算法)路由算法决定了数据包如何从源节点路由到目的节点,以最小化延迟和网络拥塞。
- Switching Strategy(交换策略)交换策略决定了数据在互连网络中如何进行传输和交换。
- Flow Control Mechanism(流量控制机制)流量控制机制确保在高负载情况下有效地管理和调节数据流量,以避免网络拥塞和数据丢失。
通信性能(Communication Performance)
Time(n)s-d = overhead + routing delay + channel occupancy + contention delay
- 开销(overhead):这是在数据传输过程中必要的固定时间开销,不随数据量的大小而变化,但是会增加整体传输时间。
- 路由延迟(routing delay):取决于路由算法的复杂度和网络拓扑的结构,较复杂的算法可能需要更长的时间来计算最佳路径。
- 通道占用(channel occupancy):描述了数据传输时,通道被其他数据包占用而导致的延迟。如果通道已被占用,数据包需要等待直到通道空闲
- 争用延迟(contention delay):在高负载时,多个节点同时尝试访问相同的资源或通道可能导致争用延迟,系统需要额外的时间来解决冲突和调度。
如何通过PFs/LDs覆盖延迟

给定一个如图所示的粗粒度阶段并行算法,参数n=256,并行性开销忽略不计
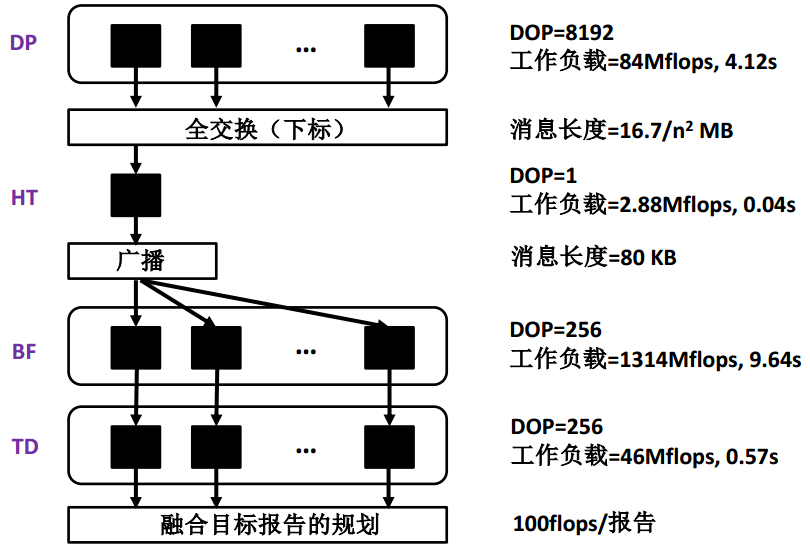

Amdahl定律
Amdahl定律是研究并行系统中最基本的定律之一,有
几个含义:
- 对于给定的工作负载,其最大加速比的上限是1/a,换言之,程序的串行成分是瓶颈,当其增加时,加速比成比例减少
- 为获取好的加速比,很重要的是应使顺序瓶颈尽可能小
- 当一个问题由以上两部分组成时,我们应设法使较大部分执行得更快
扩展的Amdahl定律指出,我们必须不仅仅是要减少串行瓶颈,而且还应增加平均颗粒度以减少开销的有害影响。换言之,并行程序的性能除了受限于串行瓶颈外,也受限于平均开销。
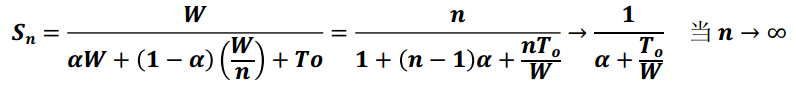
计算加速比上限

Gustafson定律
Amdahl定律的主要假设是问题规模是固定的,导致当用较大系统求解小问题时出现的报酬递减现象。John Gustafson提出了固定时间的概念,即当机器规模增大时使问题规模也扩大的方法来获取加速比的改善。
Roofline Model
包含如下基本概念
- 计算性能 (Compute Performance):通常以每秒浮点运算次数 (FLOPs) 来衡量。
- 内存带宽 (Memory Bandwidth):系统能够在单位时间内传输的数据量,通常以 GB/s 为单位。
- 算术强度 (Arithmetic Intensity):定义为计算量(FLOPs)与数据传输量(Bytes)的比值,表示每传输一字节数据能够执行的浮点运算次数。
Roofline Model图的组成 - X轴:表示算术强度 (Arithmetic Intensity),通常以对数刻度表示。
- Y轴:表示计算性能 (Compute Performance),通常以对数刻度表示。
- Roofline:由两部分组成的一条折线:
- 带宽受限区域 (Bandwidth Bound Region):当算术强度较低时,性能受限于内存带宽,表现为一条斜率为1的直线。
- 计算受限区域 (Compute Bound Region):当算术强度较高时,性能受限于计算能力,表现为一条水平线,称为计算屋顶 (Compute Roof)。
- Roofline 的拐点:带宽受限区域和计算受限区域的交点,表示从内存带宽受限到计算能力受限的过渡点。
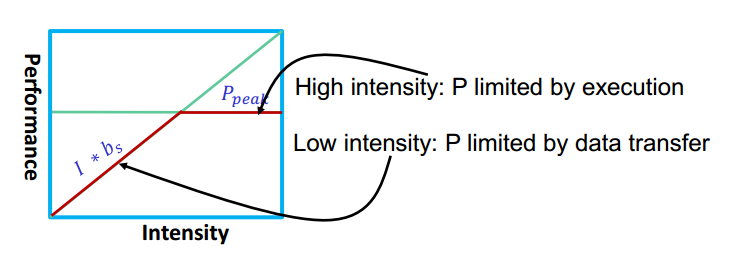
带宽受限(Bandwidth Bound)和核心受限(Core Bound)
核心受限是指应用程序的性能主要受限于处理器的计算能力,而不是数据传输速度。换句话说,处理器在忙于执行计算任务,且处理器的计算能力成为瓶颈。
带宽受限是指应用程序的性能主要受限于内存或 I/O 带宽,而不是处理器的计算能力。换句话说,系统无法为处理器提供足够快的数据传输速度,使得处理器在等待数据传输时处于空闲状态。
峰值浮点性能
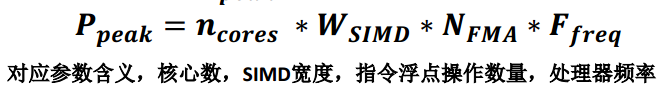
如何通过Roofline Model优化系统性能
Step1: Know your processor
- 查看CPU基本信息:lscpu
- 查看CPU cache: getconf -a | grep CACHE
- 查看numa节点信息 numactl –s, numactl –H,
- google the specific processor
- 综合对比所有信息
Step2: calculate Ppeak
Step3: benchmark available bandwidth bs - Stream benchmark https://www.cs.virginia.edu/stream/
- Likwid https://github.com/RRZE-HPC/likwid
- PE code https://github.com/PAA-NCIC/PE
Step4: application profiling - Benchmark floating-point performance
- Use profiling tools to count the memory operations
Step6: application analysis
cache miss
- 冷缓存未命中(Cold Miss / Compulsory Miss):冷缓存未命中是由于第一次访问数据时,数据尚未被加载到缓存中,因此不得不从主存中读取。这种未命中是不可避免的,因为缓存最初是空的。
- 容量缓存未命中(Capacity Miss):容量未命中发生在缓存无法容纳程序所需的全部数据时。由于缓存容量有限,当数据量超过缓存容量时,旧数据被替换,新数据需要从主存中加载,从而导致未命中。
- 冲突缓存未命中(Conflict Miss / Collision Miss):冲突未命中发生在多个数据块映射到缓存的同一个位置(缓存行或缓存槽)时,导致其中一个数据块被替换,从而造成未命中。
code balance
𝑩𝒄: code balance of the algorithm – the lower the better
𝑰𝒄 : arithmetic intensity or compute intensity of the algorithm – the higher the better
𝑩𝒄 = 1/𝑰𝒄
如何得到更大的访存带宽
- make addresses sequential:顺序的地址能够触发硬件预取器
- make address generations independent:如果一个内存访问的地址可以在不依赖之前的load的情况下被计算出来,此时cpu可以并行地发出访存。
- prefetch by software (make address generations go ahead):硬件预取器只对顺序的地址访问起作用,如果我们知道之后的计算需要的地址,我们可以在软件中进行预取。
- use multiple threads/core
每核能达到的最大访存带宽
对于Cascade Lake架构来说,Line fill buffer (LFB) is the processor resource that keepstrack of outstanding cache misses, and its size is 10 inCascade Lake.

这个数值仍然低于处理器参数表中的memory bandwidth,要想在这个基础上进一步提升带宽,唯一的办法是使用多核。
如何覆盖计算中的Latencies
- 增加并行性:我们很难让一个串行计算链更快,但我们可以运行多个独立的计算链来增加吞吐率。